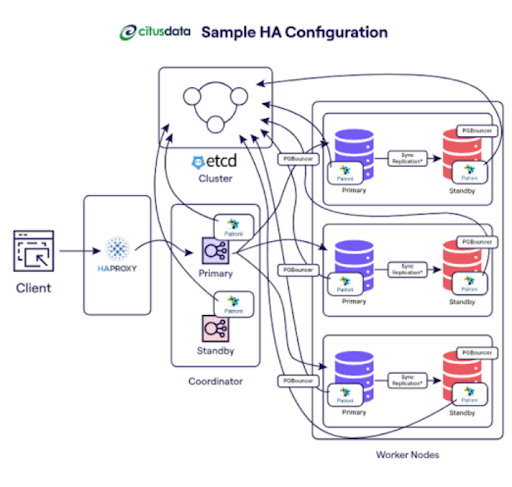
The HA metric evaluates how well a system can recover from the breakdown of its underlying infrastructure. Here, “HA” means that PostgreSQL clusters are available either in the same cloud region or across other regions, according to the design of the HA system.
Anyone interested in learning how to improve system uptime and thus PostgreSQL data-tier reliability should read this blog. Database administrators, cloud architects, as well as DevOps engineers are the target audience. Installing PostgreSQL on Compute Engine is the topic of this blog. There is no mention of Cloud SQL for PostgreSQL.
You may need a more available architecture if your system has certain quality of service objectives (SLOs). While there are other approaches to achieving HA, the most common is to set up redundant infrastructure that your app has access to rapidly.
Table of Contents
- Some factors of PostgreSQL
- When should a HA design be considered?
- Conclusion
Table of Contents
Some factors of PostgreSQL are:
Replication
The method by which write operations (INSERT, UPDATE, or DELETE) as well as schema modifications (data definition language (DDL)) get securely captured, logged, and subsequently serially propagated to all upstream database replica nodes in the design.
Terminology
Although they are outside the purview of this document, familiarity with the following industry-standard words and ideas will serve you well in other contexts.
Major node
The node which updates the state of persisted information with the most recent read. There has to be a primary node that handles every single database writes.
Time required for replication
To improve safety, the PostgreSQL Course allows flexible authentication policies, a numerical value, expressed as a time, log sequence number (LSN), or transactional ID. As a measure, replication latency is the time it takes to apply changes to the replica as opposed to the main node.
Alternative (secondary) node
Another node in the main database that is accessible online. From the main node, changes can be replicated either simultaneously or asynchronously to the replica node. If you’re willing to wait a little longer than usual for data to arrive from replica nodes, you are able to read from them.
On-going preservation
The database incrementally backs up itself by saving consecutive transactions to a file in a continuous fashion.
WAL record
A log of a database operation. The format and storage of a WAL record is a sequence of entries that reveal modifications made at the page level in a data file.
Write-ahead log (WAL)
An example of log files can be a write-ahead log (WAL), which documents modifications to data files in advance of their actual modification. The WAL is a common method for protecting your data analysis as well as making sure your writes will last in the event of a server failure.
A logarithmic sequence number
Each transaction adds a new WAL record to the existing WAL file. An LSN, or Log Sequence Number, identifies the exact location of the insert. Two hexadecimal digits split by a slash (XXXXXXXX/YYZZZZZZ) indicate that it is a 64-bit integer. With the letter “Z,” you may find the offset in the WAL file.
Simultaneous copying
This kind of replication requires the secondary server to verify the data’s presence in its transaction log so the main server can validate the commit to the client’s computer. The PostgreSQL asynchronous commit option allows you to set up consistency assurances when doing streaming replication.
Dividing up data
Files have an unlimited number of WAL records, determined by the file size settings you choose. The standard measurement of a segment file is 16 MB, although its name grows monotonically larger over time.
Replication
A type of replication where the main server commits data to the client without waiting for the replica to validate the transaction’s success. There is less latency with asynchronous duplication than with synchronous replication. Nevertheless, data loss may occur if the original database collapses without transferring its transactions that were committed to the replica. Whether you’re utilizing streaming replication or file-based log shipping, PostgreSQL always uses asynchronous replication.
Replicating streaming
This technique for replicating data involves maintaining a constant flow of updates by linking the replica to the main database. Relative to log-shipping replication, this technologies maintains the replica more current with the original as updates occur through a stream. You have the option to set up synchronous replication, even if it is by design asynchronous.
PostgreSQL replication
A PostgreSQL replication procedure that copies the WAL segment files from the original database to the copy. Each backup service reads WAL files in constant recovery mode, while the primary runs in continuous archiving mode. Each replication happens at different times.
Reproduction of physical streaming
A technique for duplicating data that transfers modifications to the copy. To implement this strategy, it makes use of the WAL records, which provide the updated physical data as disk block addresses plus byte-by-byte modifications.
Uptime
The fraction of time when a system is actively processing requests and has the capability to respond to them.
Replicating logic streams
There is more oversight of the data replication process with this method than with physical replication since it captures changes depending on their replication identity (primary key). Logical stream replication necessitates certain configuration in a HA solution due to limitations in PostgreSQL logical replication. Logical replication is outside the scope of this manual, which focuses on conventional physical duplication.
Detection of failures
The steps taken to determine that a breakdown in the infrastructure has taken place.
Switchover
Performing a manual failover in a production environment. Performing a switchover either verifies that everything is running smoothly or removes the principal node from the cluster for upkeep.
Backup plan
Moving the replica node, which is the secondary or standby infrastructure, up the priority ladder to become the main infrastructure. The replica node takes over as the main node during failure.
Recovery time
Duration in real-time that the data tier failover operation took to finish. The allowed amount for time from an organization’s standpoint determines RTO.
Backup plan
Bringing back the previous primary node upon fixing the issue that triggered the failover.
Rarget for recovery (RPO)
The data tier’s ability to withstand failover data loss in terms of time in real-time. What is an acceptable level of data loss given a business standpoint determines the RPO.
Intervention
A system’s capacity to fix problems without intervention from a human operator.
Leading node
A state in which two nodes mistakenly think that they are the leading node at the same time.
Partitioning network
A state in which two architectural nodes, such as the main as well as replica nodes, are unable to exchange data with one another in a network.
Network set
A collection of computing resources that offer a service. This data persistence tier is a very important service.
Preliminary
The procedure by which a cluster of nodes that are aware of their peers and other nodes that are acting as witnesses decide which node will take the lead.
Observer or quorum
A distinct computational resource that aids a cluster of nodes in deciding how to handle a split-brain scenario.
When should a HA design be considered?
When it comes to data-tier downtime, HA architectures offer more protection than single-node database systems. Knowing your downtime threshold and the benefits and drawbacks of each architecture can help you choose the one that’s most suited to your company’s use case.
To satisfy the dependability needs of your workloads as well as services, implement a HA architecture to boost the data-tier uptime. You may be wasting money and effort with a HA design if your organization can handle a little bit of downtime. For instance, high database tier reliability is not often required for development or testing settings.
Take into account your needs for HA
If you are trying to figure out which PostgreSQL HA option is ideal for your company, consider the following questions:
- How much would your company lose if your data retention tier went down? Which services and clients depend on it?There is less of a need for availability in any service that only services internal clients who only use the system sometimes compared to a service which serves end users all the time.
- When you say “availability,” what does it mean? Is the ability to keep your service running in the event of a regional outage or failure of just a single zone what you need? There are HA alternatives that are region-specific and others that can cover many regions.
- How fast must you fail over, as well as how fully automated must the procedure be? (Asking for your RTO) The choices for high availability (HA) differ according to the system’s failover as well as availability speed.
- Could you tell me your operating budget? One important factor to think about is the cost. If you want to offer HA, your infrastructure plus storage expenses will probably go up.
- Is it acceptable to risk data loss during the failover? Can you tell me your RPO? Commit delay and failure-related data loss are two competing concerns in HA topologies caused by their global architecture.
Conclusion
To process queries for data inquiries or changes, the data persistent layer, also known as the data tier, needs to be accessible if an application or system needs a permanent state for handling transactions or requests. When the data tier is down, a system or app can’t do what it needs to.